YugabyteDB is resilient to a single-domain failure in a deployment with a replication factor (RF) of 3. To survive zone failures, you deploy across multiple zones. Let's see how YugabyteDB survives a zone failure.
## Setup
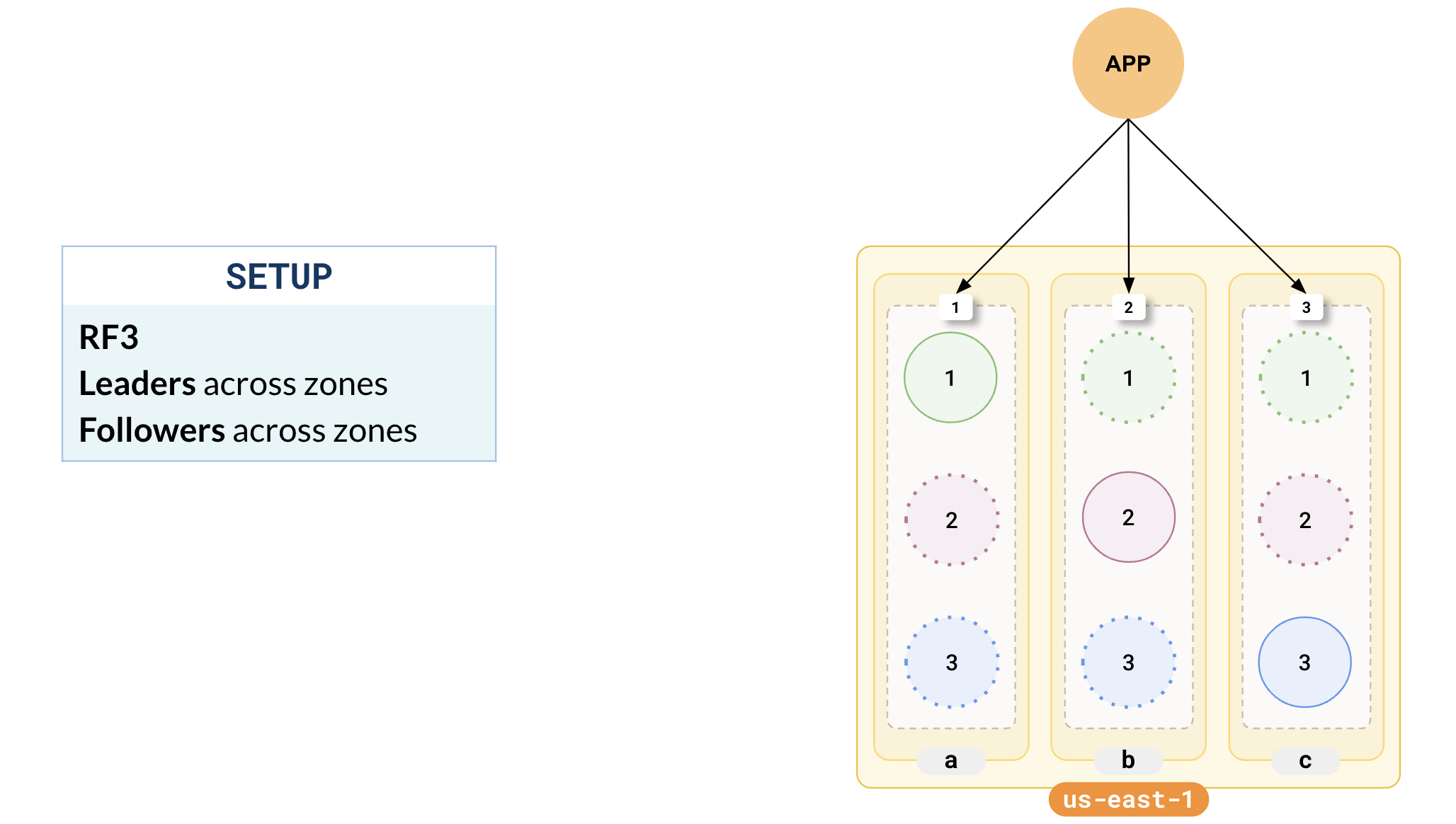
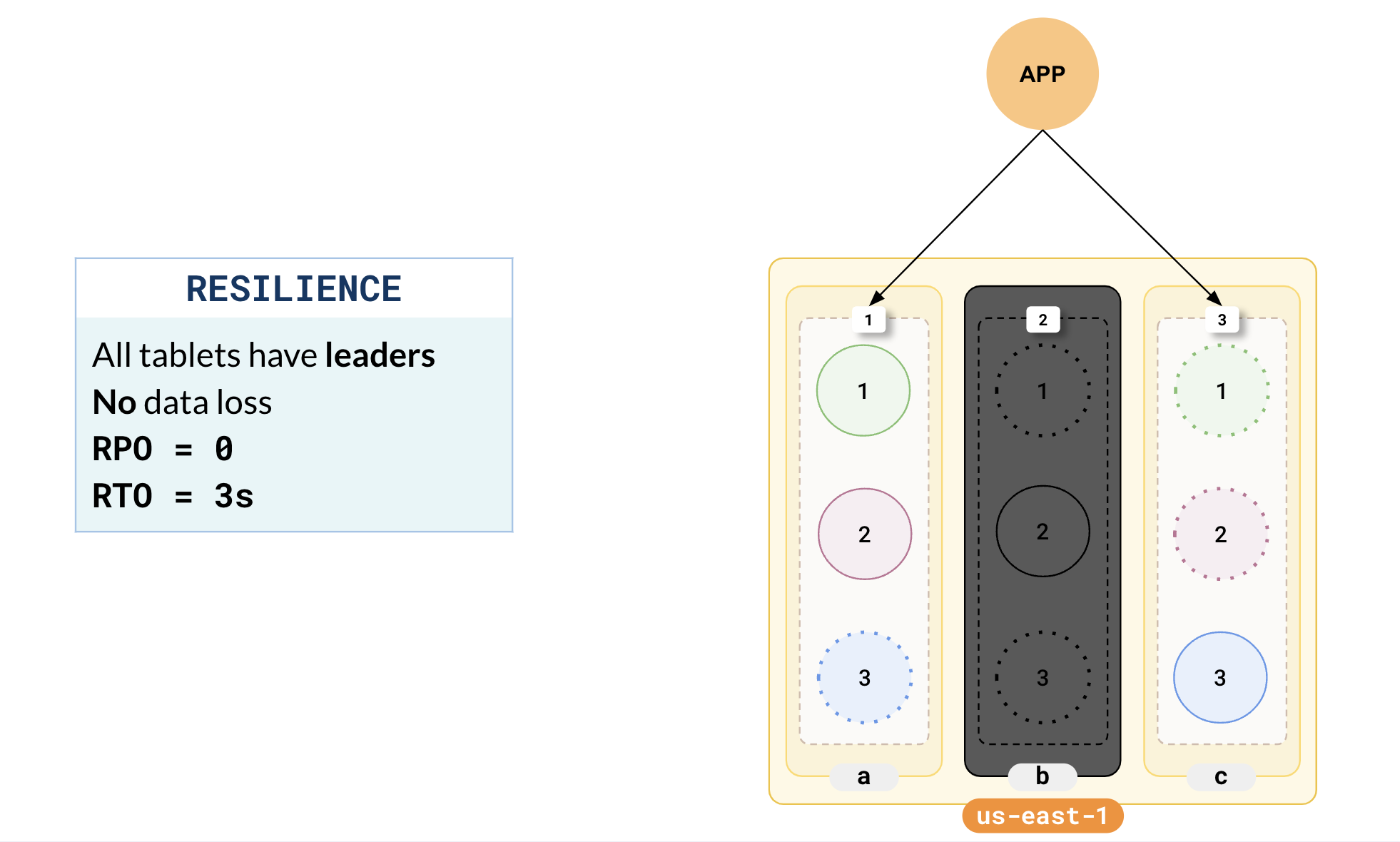
Consider a setup where YugabyteDB is deployed across three zones in a single region (us-east-1). Say it is an RF 3 cluster with leaders and followers distributed across the 3 zones with 3 tablets (A, B, and C).
{{}}
{{}}
## Zone fails
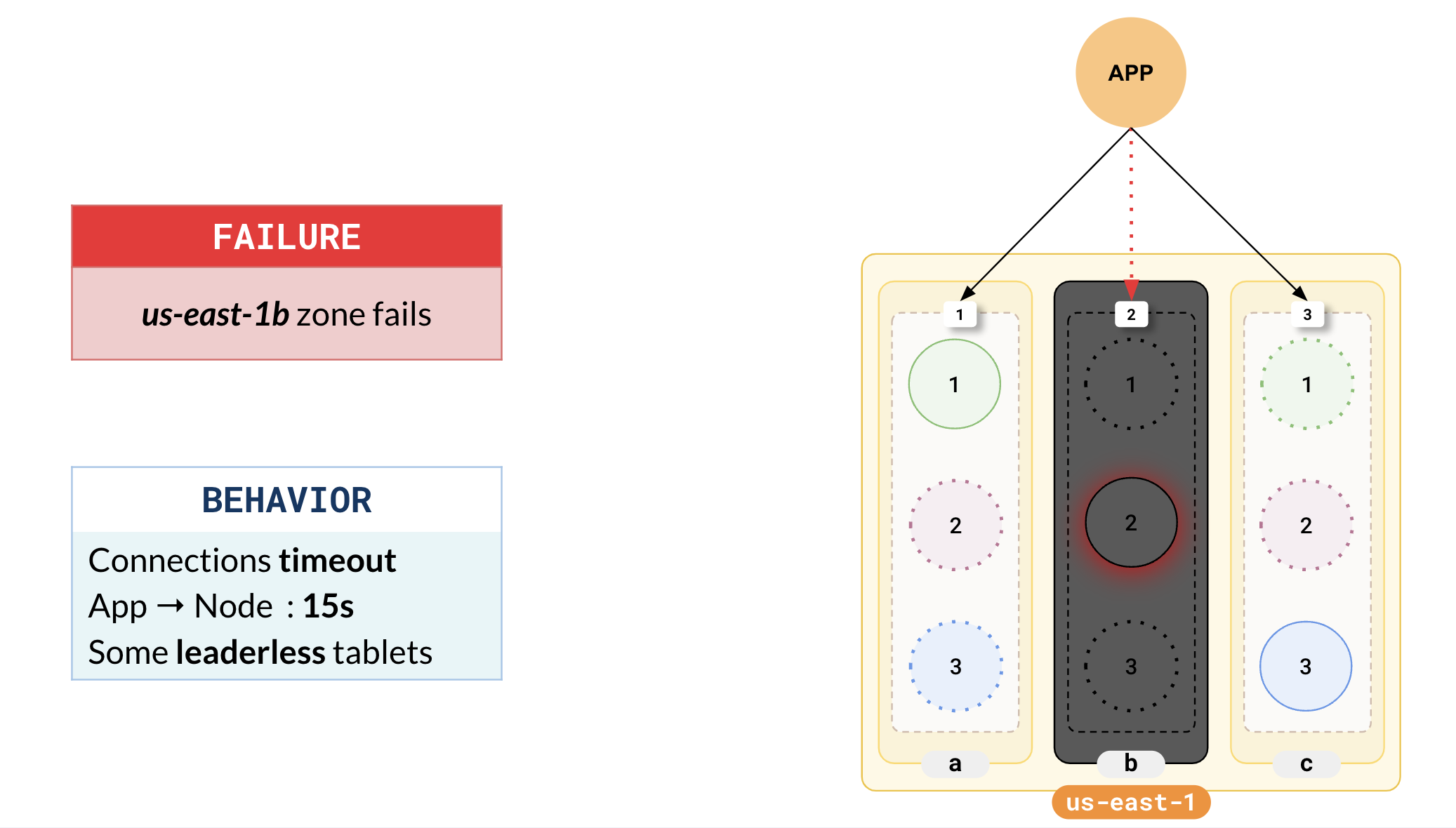
Suppose one of your zones, us-east-1b, fails. In this case, the connections established by your application to the nodes in us-east-1b start timing out (typical timeout is 15s). If new connections are attempted, they will immediately fail, and some tablets will be leaderless. In the following illustration, tablet B has lost its leader.
{{}}
{{}}
{{}}
All illustrations adhere to the legend outlined in [Legend for illustrations](../../../contribute/docs/docs-layout#legend-for-illustrations)
{{}}
For example, in the following illustration, tablet B has lost its leader.
## Leader election
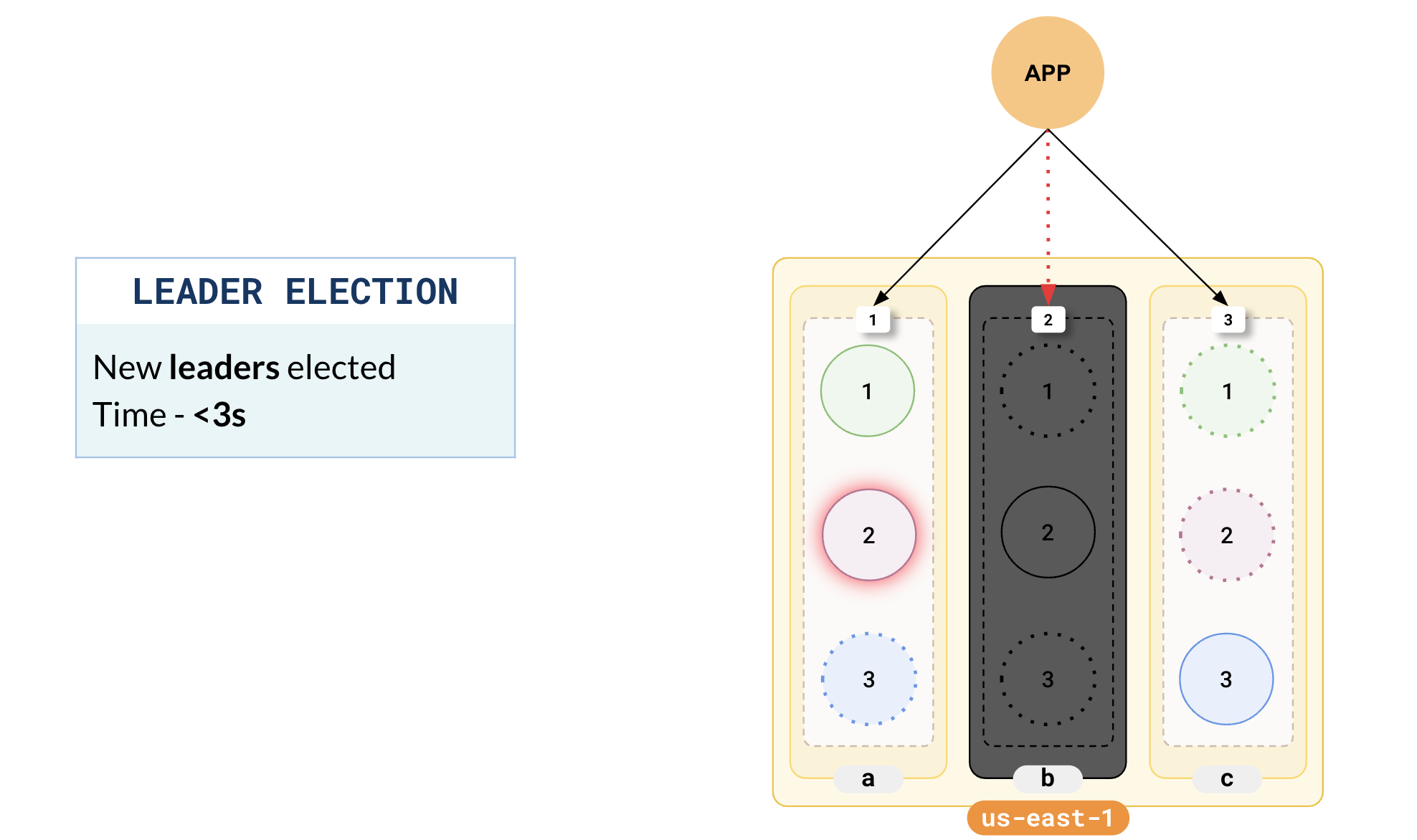
All the nodes in the cluster constantly ping each other for a liveness check. When a node goes offline, it is identified within 3s and a leader election is triggered. This results in the promotion of one of the followers of the offline tablets to leaders. Leader election is very fast and there is no data loss.
In the illustration, you can see that one of the followers of the tablet B leader in zone-a has been elected as the new leader.
## Cluster is fully functional
Once new leaders have been elected, there are no leader-less tablets and the cluster becomes fully functional. There is no data loss as the follower that was elected as the leader has the latest data (guaranteed by Raft replication). The recovery time is about 3s. But note that the cluster is now under-replicated because some of the followers are currently offline.
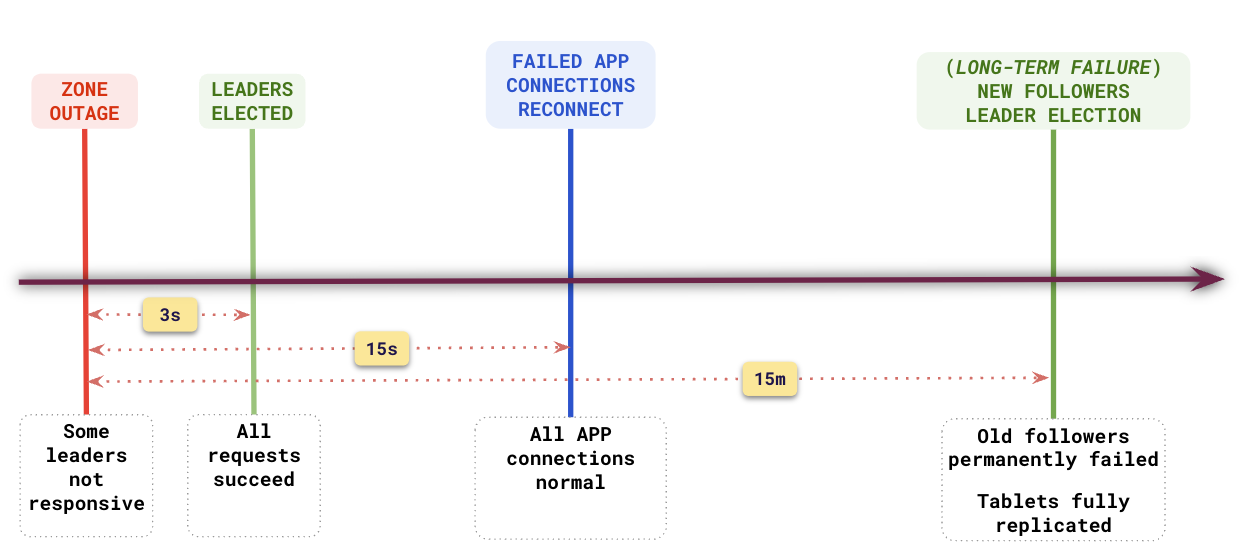
## Recovery timeline
From the point a zone outage occurs, it takes about 3s for all requests to succeed as it takes about 3s for the cluster to realize that nodes are offline and complete a leader election. Because of default TCP timeouts, connections already established by applications will take about 15s to fail and on reconnect, they will reconnect to other active nodes.
At this point, the cluster is under-replicated because of the loss of followers. If the failed nodes don't come back online within 15 minutes, the followers are considered failed and new followers will be created to guarantee the replication factor (3). This in essence happens only when the failure of nodes is considered to be a long-term failure.