For a highly available system, it is typical to opt for a [Global database](../global-database) that spans multiple regions with preferred leaders set to a specific region. This is great for applications that are running in that region as all the reads would go to the leader located locally.
But applications running in other regions would incur cross-region latency to read the latest data from the leader. If a little staleness for reads is acceptable for applications running in the other regions, then **Read Replicas** is the pattern to adopt.
A read replica cluster is a set of follower nodes connected to a primary cluster. These are purely observer nodes, which means that they don't take part in the Raft consensus and elections. This also means that read replicas can have a different replication factor (RF) from the primary cluster, and the RF can be an even number.
{{}}
Multiple application instances are active and some instances read stale data.
{{}}
## Setup
{{}}
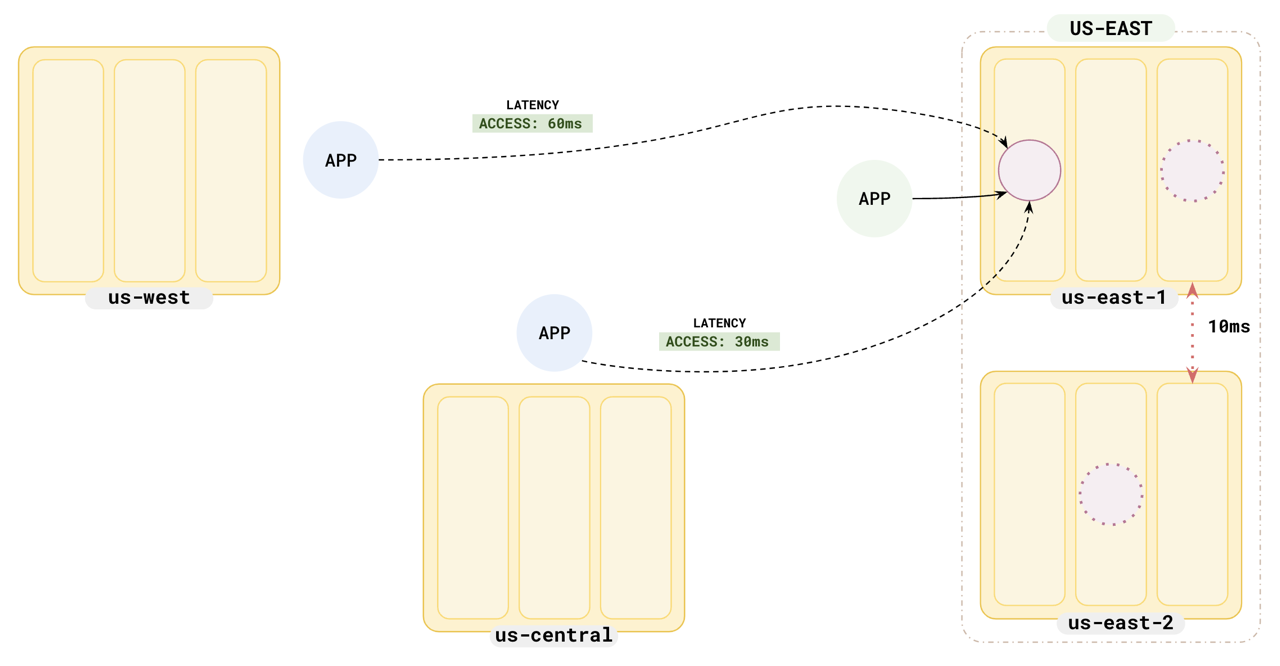
Suppose you have a replication factor 3 cluster set up in `us-east-1` and `us-east-2`, with leader preference set to `us-east-1`, and you want to run other applications in `us-central` and `us-west`. The read latencies would be similar to the following illustration.
## Improve read latencies
To improve read latencies for applications where a little staleness is acceptable, you can set up read replica clusters in each of the regions where you want to run your application. This enables the application to read data from the closest replica instead of going cross-region to the tablet leaders.
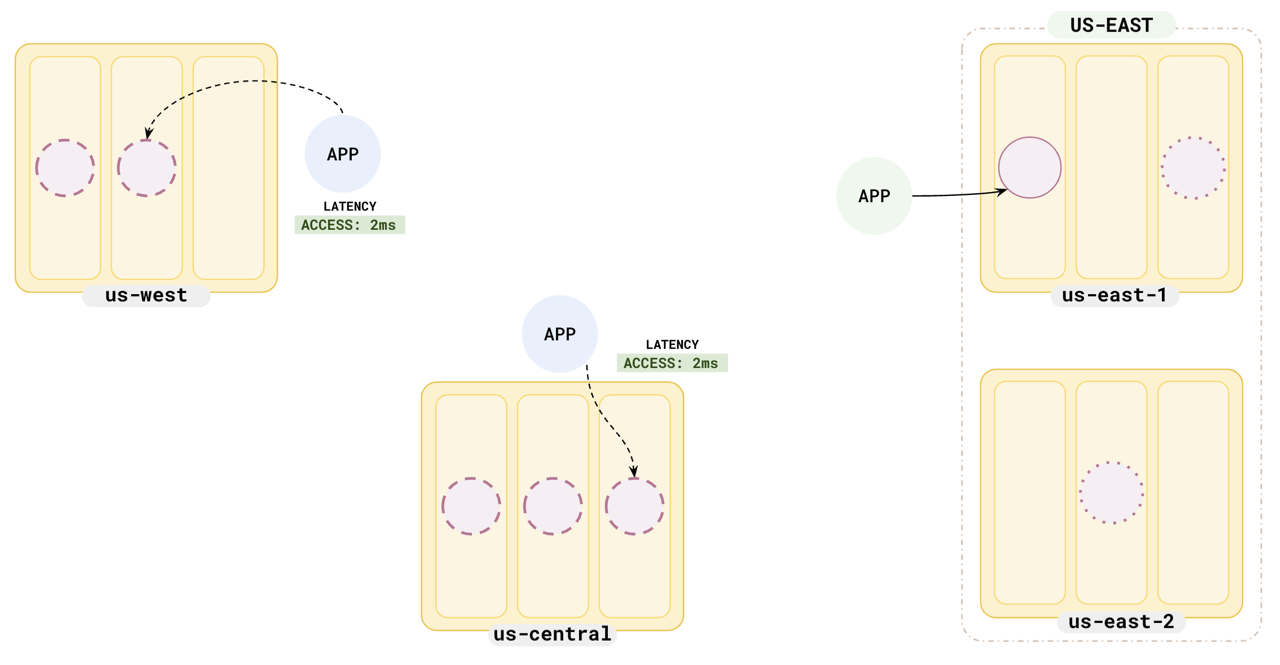
Notice that the read latency for the application in `us-west` has drastically dropped to 2 ms from the initial 60 ms and the read latency of the application in `us-central` has also dropped to 2 ms.
As replicas may not be up to date (by design), this might return slightly stale data (default: 30s).
{{}}
This is only for reads. All writes still go to the leader.
{{}}
## Failover
When the read replicas in a region fail, the application redirects its reads to the next closest read replica or leader.
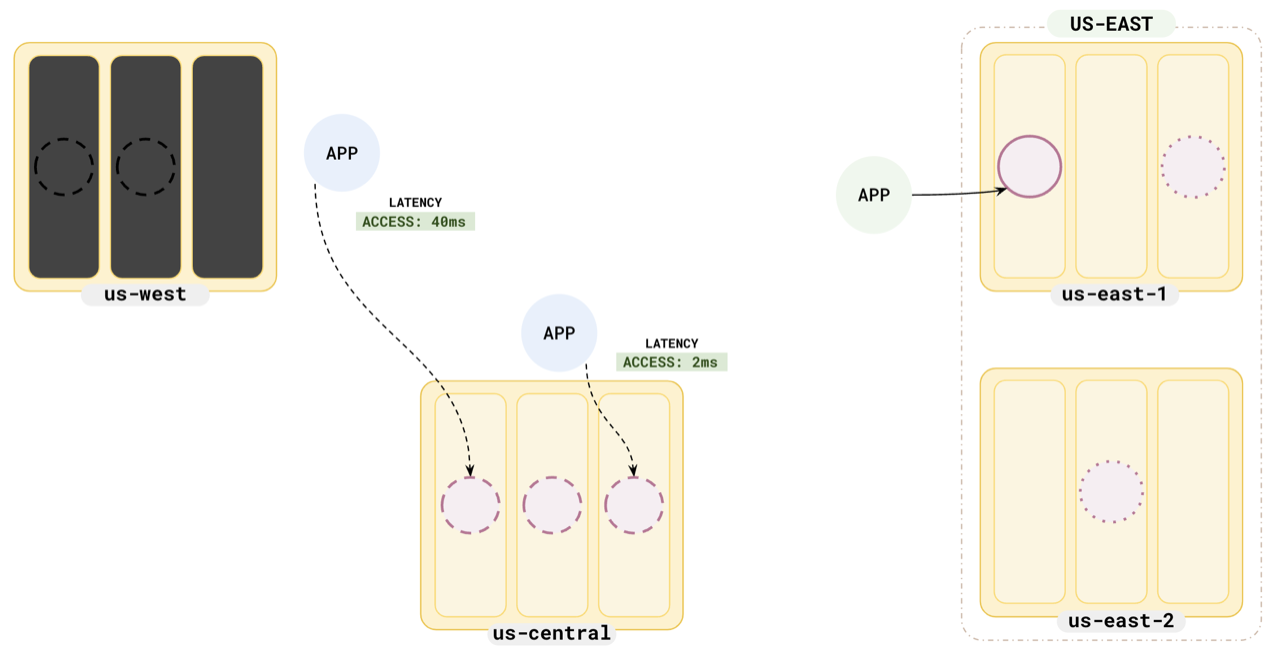
Notice how the application in `us-west` reads from the follower in `us-central` when the read replicas in `us-west` fail. The read latency is 40 ms, still much less than the original 60 ms.
## Example scenario
### Applications in multiple geographies
Suppose that you have applications in three geographies, say `us`, `eu`, and `sg`. You could set up a [global database](../global-database) that spans the three geographies, and set preferred leaders to one geography where you have the most users (say `eu`). But this means that all application writes have to be replicated to at least one other geography (other than `eu`). This could lead to increased write latency, although applications in other geographies could use [follower reads](../follower-reads) to read slightly stale data with reduced latency.
In this scenario, you could consider setting up your global database in `eu`, and add separate read replica clusters in `us` and `sg`. This would ensure low latency for writes as replication happens in the same geography and at the same time, data will be replicated quickly to the read replica clusters ensuring low read latency for users in `us` and `sg`.
{{}}
Although this would involve more nodes than a basic RF3 global database, it ensures low latency for both writes and stale reads.
{{}}
## Learn more
- [Read replica architecture](../../../architecture/docdb-replication/read-replicas)