For applications that run in a single region but need a safety net, you can adopt the **Active-Active Single-Master** pattern. This involves setting up two clusters in different regions. One cluster actively handles all reads and writes, while asynchronously replicating data to the second cluster. The second cluster can serve transactionally consistent but slightly stale reads. In the event of a failure of the first cluster, the second cluster can be promoted to Primary, a process known as **Disaster Recovery**. This setup is particularly useful when you have only two regions, or you want to deploy the database in only one region for low latency writes, while maintaining another copy in the other region for failover and low latency reads.
{{}}
Only one application instance is actively writing at any time. A replica cluster serves transactionally consistent reads and can be promoted to Primary in case of failure.
{{}}
## Setup
{{}}
Suppose you have cluster with a replication factor of 3, and applications deployed in `us-west`.
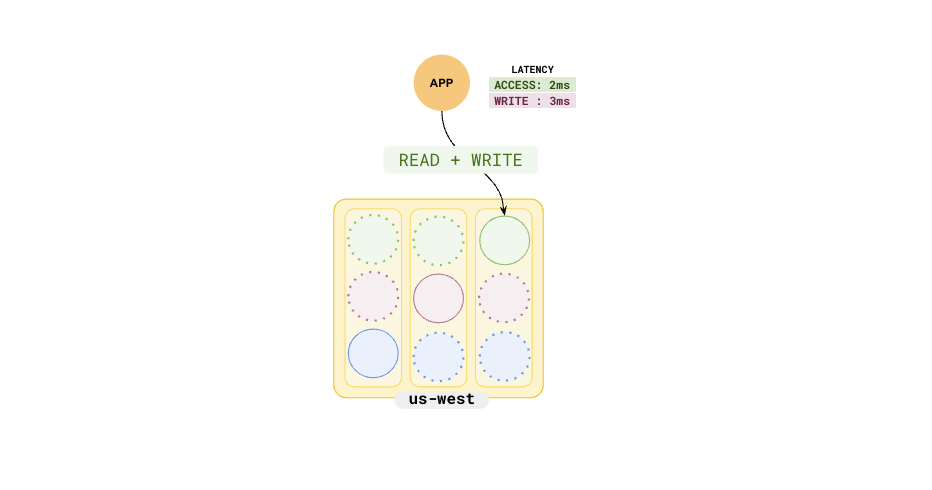
This ensures that the reads and writes are in the same region, with the expected low latencies. Because the entire cluster is in a single region, in case of a region failure, you would lose all the data.
## Secondary replica cluster
You can set up a secondary cluster in a different region, say `us-east`, using [Transactional xCluster Setup](../../../deploy/multi-dc/async-replication/async-transactional-setup-automatic).
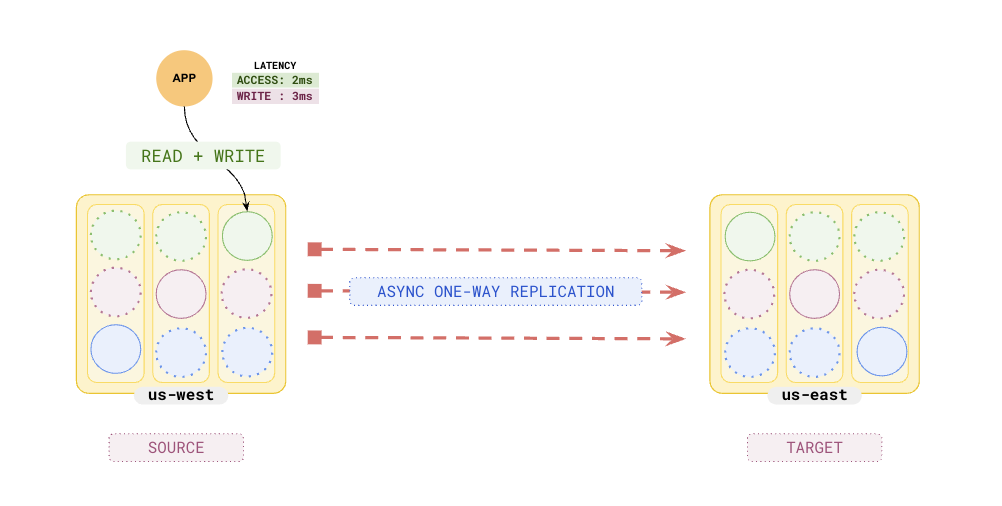
The `us-east` cluster (_Standby_) is independent of the primary cluster in `us-west` and the data is populated by **asynchronous replication** from the `us-west` cluster (_Primary_). This means that the read and write latencies of the Primary cluster are not affected, but at the same time, the data is not immediately available on the Standby cluster. The _Standby_ cluster acts as a **replica cluster** and can take over as Primary in case of a failure.
This can also be used for [blue-green](https://en.wikipedia.org/wiki/Blue-green_deployment) deployment testing.
## Local reads
Because the second cluster has the same schema and the data (with a short lag), it can serve stale but transactionally consistent reads for local applications.
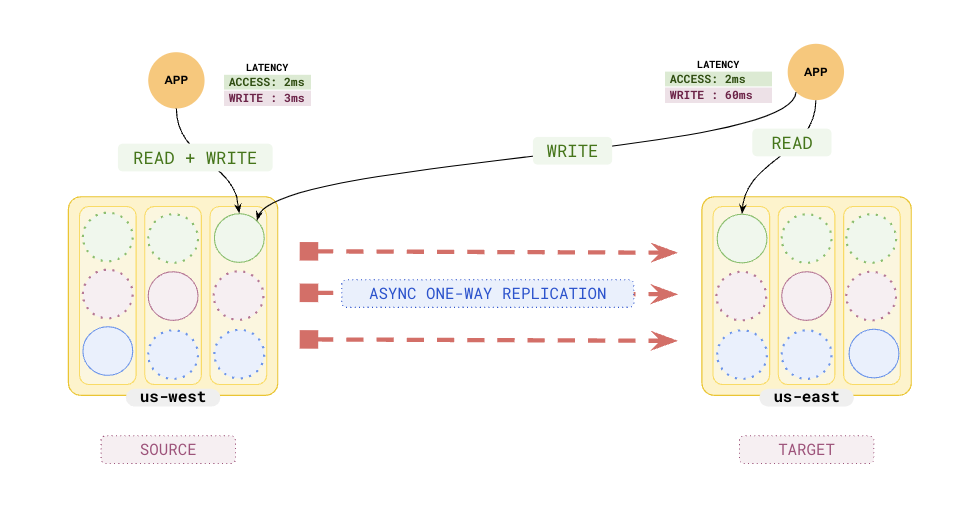
Writes still have to go to the primary cluster in `us-west`.
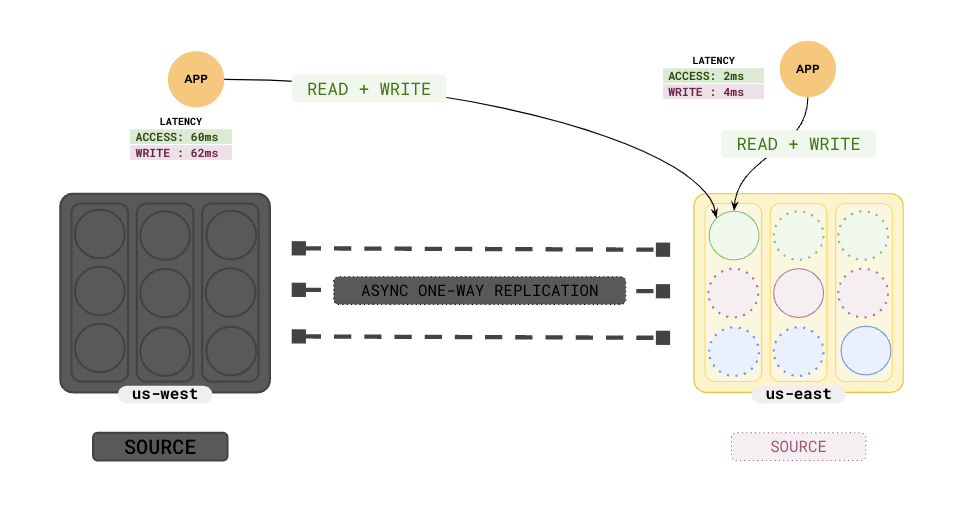
## Failover
When the Primary cluster in `us-west` fails, the Standby cluster in `us-east` can be promoted to become the primary and can start serving both reads and writes.
## Learn more
- [xCluster architecture](../../../architecture/docdb-replication/async-replication)