For applications that have to be run in multiple regions, you can adopt the **Active-Active Multi-Master** pattern, where you set up two clusters in two different regions, and both clusters actively take responsibility for local reads and writes and replicate data **asynchronously**. In this case, failover is manual and incurs possible loss of data, as the data is asynchronously replicated between the two clusters, but both reads and writes have low latencies.
{{}}
Application instances are active in multiple regions and may read stale data.
{{}}
## Overview
{{}}
Suppose you have cluster with a replication factor of 3, and applications deployed in `us-west`.
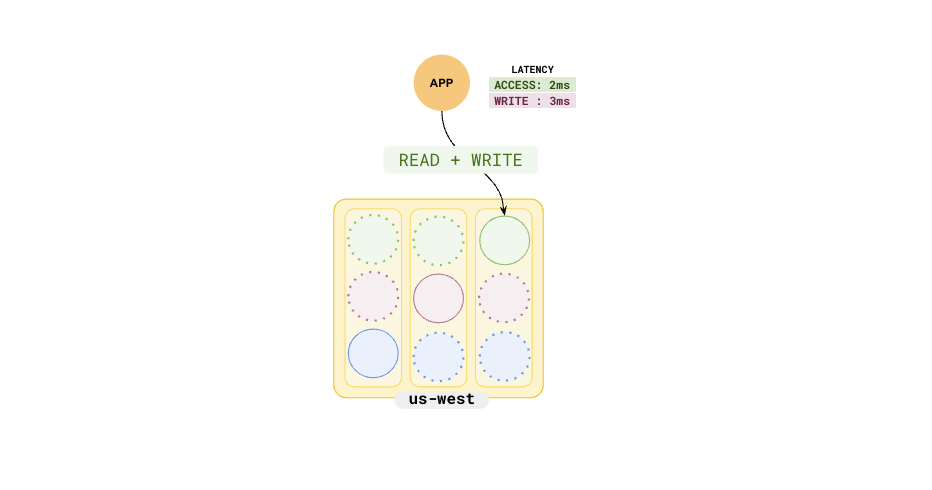
This ensures that the reads and writes are in the same region, with the expected low latencies. Because the entire cluster is in a single region, in case of a region failure, you would lose all the data.
## Multi-master
You can eliminate the possibility of data loss by setting up another cluster in a different region, say `us-east`, using [xCluster Setup](../../../deploy/multi-dc/async-replication/async-deployment).
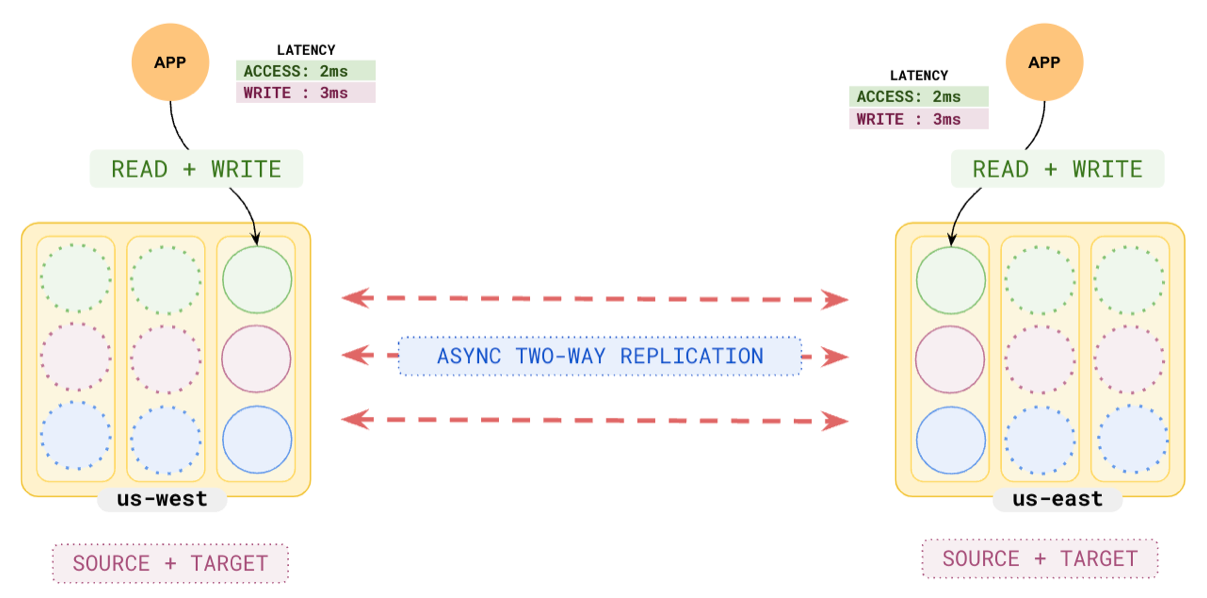
The `us-east` cluster is independent of the primary cluster in `us-west` and the data is populated by **asynchronous replication**. This means that the read and write latencies of each cluster are not affected by the other, but at the same time, the data in each cluster is not immediately consistent with the other. You can use this pattern to reduce latencies for local users.
## Transactional consistency
The **Active-Active Multi-Master** pattern does not guarantee any transactional consistency during the replication between the clusters. Conflicts are resolved in the bi-directional replication by adopting the "last-writer wins" strategy.
## Failover
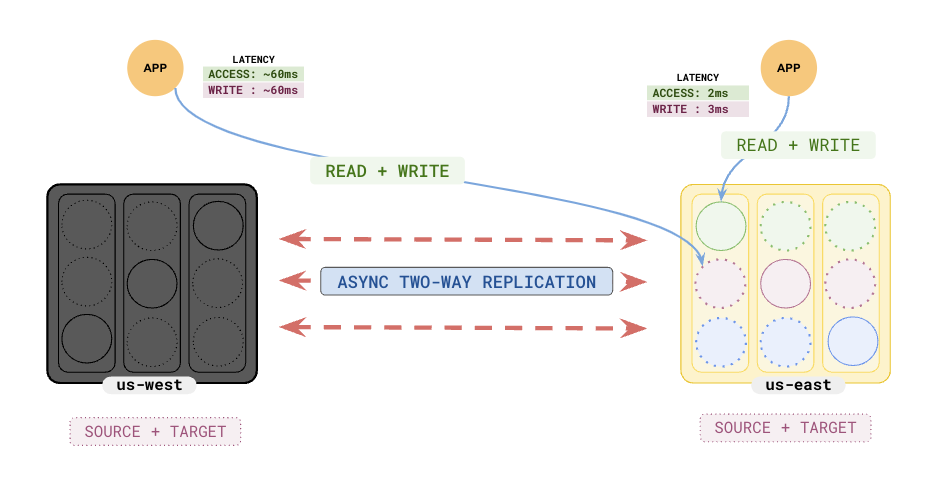
When one of the clusters fails, say `us-west`, the other cluster in `us-east` can handle reads and writes for all applications until the failed region recovers.
## Learn more
- [xCluster architecture](../../../architecture/docdb-replication/async-replication)